2024年8月27日——近日,在2024年Hot Chips大会上,英特尔展示了其技术的全面与深度,涵盖了从数据中心、云、网络和边缘到PC的各个领域AI用例,并介绍了其业界领先且完全集成的OCI(光学计算互连)芯粒,可用于高速AI数据处理。此外,英特尔还披露了关于英特尔® 至强® 6系统集成芯片(代号Granite Rapids-D)的最新细节,该产品预计将于2025年上半年发布。
英特尔网络与边缘事业部首席技术官Pere Monclus表示:“针对各种消费和企业级AI的应用场景,英特尔不断提供其创新所需的平台、系统和技术。随着AI工作负载不断增长,英特尔广泛的行业经验使我们能够了解客户的真正需求,以此推动创新、创意和理想商业成果落地。尽管性能更高的芯片和更高的平台带宽至关重要,但英特尔深知每种工作负载都有其独特的挑战。因此,为数据中心设计的系统不能简单地被重新应用于边缘。英特尔在所有计算系统架构方面所拥有的经过验证的专业知识,将更好地为下一代AI创新提供动力。”
在Hot Chips 2024大会上,英特尔发表了四篇技术论文,重点介绍了英特尔® 至强® 6系统集成芯片、Lunar Lake客户端处理器、英特尔® Gaudi 3 AI加速器以及OCI(光学计算互连)芯粒。
为边缘而生:下一代英特尔® 至强® 6系统集成芯片
英特尔院士、网络与边缘芯片架构师Praveen Mosur公布了英特尔® 至强® 6系统集成芯片设计的最新细节,以及它如何能够解决边缘使用场景中存在的特定挑战,例如网络连接的不稳定以及有限的空间和电力。得益于从全球超过9万次1边缘部署中获得的经验,英特尔® 至强® 6系统集成芯片将成为英特尔迄今为止针对边缘场景优化程度最高的处理器。通过从边缘设备扩展到边缘节点使用单一系统架构和集成AI加速能力,企业可以更轻松、高效、安全地管理从数据摄取到推理的整个AI工作流程,从而帮助改善决策、提高自动化水平,并为其客户创造价值。
英特尔® 至强® 6系统集成芯片结合了英特尔® 至强® 6处理器的计算芯粒,以及采用了Intel 4制程工艺的针对边缘进行了优化的I/O芯粒,使该系统集成芯片在性能、能效和晶体管密度方面与前代系统集成芯片相比获得了显著提升。英特尔® 至强® 6系统集成芯片的其它特性还包括:
•支持高达32条PCI Express(PCIe)5.0通道。
•支持多达16条Compute Express Link(CXL)2.0通道。
•拥有2x100G以太网。
•在兼容的BGA封装中提供4个或8个内存通道。
•拥有专为边缘环境优化的特性,包括更大的运行温度范围和工业级可靠性,使其成为高性能耐用设备的理想选择。
英特尔® 至强® 6系统集成芯片还包括了用于提高边缘和网络工作负载的性能和效率的功能特性,包括:新的媒体加速功能,可增强实时OTT、点播(VOD)和广播媒体的视频转码和分析;英特尔® 高级矢量扩展和英特尔® 高级矩阵扩展(英特尔® AMX),可提高推理性能;英特尔® 快速辅助技术(英特尔®QAT),可实现能效更高的网络和存储性能;英特尔® vRAN Boost,可降低虚拟化RAN的功耗;以及支持英特尔®Tiber™ 边缘平台,该平台使用户能够在标准硬件上构建、部署、运行、管理和扩展边缘和AI解决方案,具有类似云的简洁性。
Lunar Lake:驱动下一代AI PC
英特尔客户端CPU SoC首席架构师Arik Gihon讨论了Lunar Lake客户端处理器,以及它如何为x86架构的能效树立新标杆,同时提供出色的核心、图形和客户端AI性能。新的性能核(P核)和能效核(E核)所提供的出色性能,使SoC的功耗相比上一代最多降低了40%。新的神经网络处理单元(NPU)速度提升多达4倍,与上一代相比,使生成式AI能力也获得了相应提升。此外,与前代产品相比,全新的Xe2图形处理单元核心将游戏和图形性能提高了1.5倍。

即将于9月3日举行的英特尔酷睿Ultra发布会将公布有关Lunar Lake的更多细节。
英特尔® Gaudi 3 AI加速器:针对生成式AI的训练和推理而设计
AI加速器首席架构师Roman Kaplan指出,生成式AI模型的训练与部署对算力提出了极为严苛的要求。随着系统规模从单节点扩展至数千节点的庞大集群,这使得成本与能效也迎来巨大挑战。

英特尔® Gaudi 3 AI加速器能够有效应对上述挑战。该加速器通过创新的架构——优化的计算、内存和网络架构,高能效矩阵乘法引擎、两级缓存集成,以及广泛的RoCE网络(以太网融合RDMA技术)等策略,使得Gaudi 3 AI加速器能够实现卓越的性能与能效,助力AI数据中心以低成本、可持续的方式运行,并解决了部署生成式AI工作负载时的扩展性问题。
英特尔将在今年9月分享Gaudi 3 AI加速器和未来英特尔至强6产品的更多信息。
传输速度高达4 Tbps的光学计算互连(OCI)芯粒,用于XPU之间的连接
英特尔硅光集成解决方案(IPS)团队展示了业界领先、完全集成的OCI芯粒与英特尔CPU封装在一起时,运行真实数据的情况。
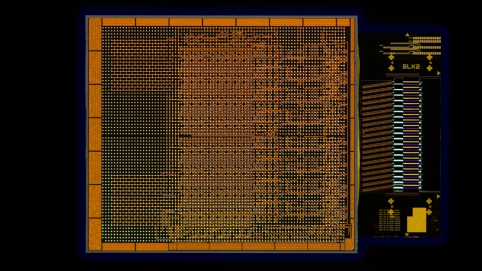
硅光集成解决方案事业部光子芯片架构师Saeed Fathololoumi介绍了这一OCI芯粒及其设计。该芯粒可在最长可达100米的光纤上,单向支持64个32 Gbps通道。Fathololoumi还讨论了该芯粒如何满足AI基础设施对更高带宽、更低功耗和更长传输距离日益增长的需求。英特尔的OCI芯粒推动了高带宽互连技术的进步,将有助于实现可扩展的CPU和GPU集群连接以及新型计算架构,包括新兴AI基础设施中的一致性内存扩展及资源解耦,适用于数据中心和HPC(高性能计算)应用。
AI让企业和消费者有机会更快地推进创新。例如,消费者现在可以选择AI PC,通过智能化功能提高效率、创造力、游戏和娱乐体验以及安全性,而企业则可以利用强大的边缘计算和AI来改善决策,提高自动化水平,并从专有数据中获取价值。
在Hot Chips 2024的深度技术研讨会上,英特尔的不同产品团队还展现了独到的技术洞见,以共同推动下一代AI技术的市场化进程。










































 京公网安备 11010202008829号
京公网安备 11010202008829号